
## 一、背景:
- 上周末leader要求对安全厂商的公众号发布信息进行追踪,要求及时匹配到关键信息,也好及时通告客户。
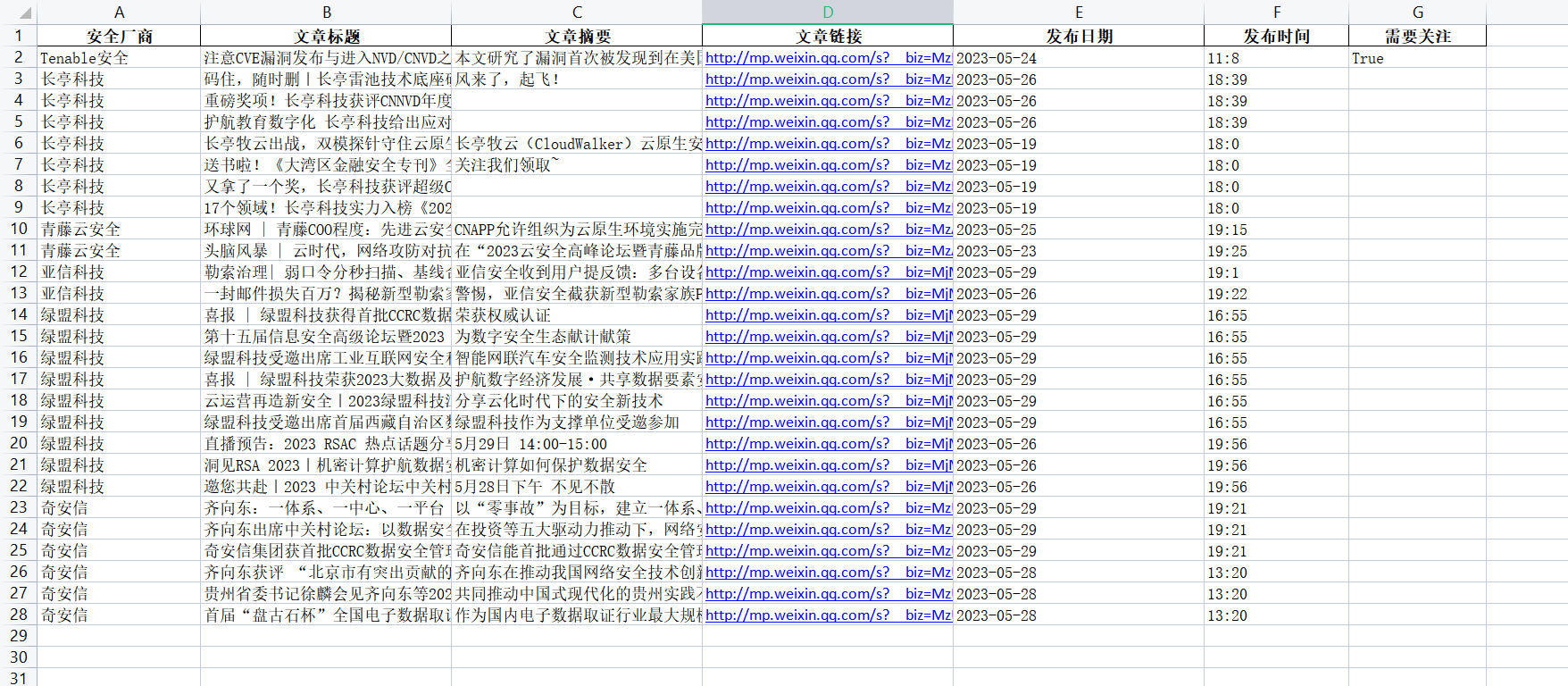
- 效果:
## 二、实现:
- 难点:微信公众平台未开放某公众号的文章查询接口,每一篇文章的URL链接和发布公众号没有绑定特征。故而无法直接采用url内容解析爬取的形式收集某个公众号的已发布文章。
- 解决方案 : 利用微信公众平台的发布文章时的超链接功能,抓到可以对某一公众号已发布文章内容进行读取。
- 缺点1:该方式需要使用`Cookie`,但`cookie`存在有效期限问题~~
- 缺点2:该方式还需要使用公众号平台的`token`参数,该`token`每天都会变动,体现在请求链接的参数中~~~
- 缺点3:方式无法频繁请求,频繁操作将会导致该接口的请求操作被封一天
- 优点:
- 可以批量对多个公众号进行数据抓取,数据为`JSON`字段,方便后续处理
- 仅需要微信公众平台的`cookie` 以及请求`token`两个参数即可实现数据抓取
- 前置操作—获取微信`cookie`以及`url`:[传送门](https://zhuanlan.zhihu.com/p/593939615)
## 三、代码:
- 完整代码:[下载](https://owncloud.gotarget.top/d/Data/Code/Dev/Check_Offical_Account_Articl.zip)
- 核心数据处理代码:
```
# @Author: Adil
# @Date: 2023-05-28 15:00:34
# @Describe: 查询厂商公众号发布的信息,对最近两次发布的文章进行处理(一天一次,当天可能发布多条文章)
import requests
import datetime
import pandas as pd
import re
import time
# 创建全局变量,用于存储取得的文章基本信息
aritcle_lists = []
# 创建全局变量,用于获取当前日期,判断文章是否新发,进而触发下一步操作
today = str(datetime.date.today())
# 创建正则的判定表达式
rule = r"(cve)|(漏洞)|(通告)|(告警)|(紧急)"
def query_info(offical_account,cookie,Query_Token):
# 设定基础请求接口
base_url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
# 厂商公众号的ID
fakeid_dict = {'Tenable安全':'MzIyMTg0MTE3MA==','长亭科技':'MzIwNDA2NDk5OQ==','青藤云安全':'MzAwNDE4Mzc1NA==' ,'亚信科技':'MjM5NjY2MTIzMw==','绿盟科技':'MjM5ODYyMTM4MA==','奇安信':'MzU0NDk0NTAwMw=='}
# 请求参数
params = {
"action": "list_ex",
"begin": 0, # 查询启示页,默认每页5条数据
"count": 2, # 查询最近两天次内发布的信息(一天一次,一次可以发布多条文章)
"fakeid": fakeid_dict[offical_account], # 公众号的标识ID
"type": 9,
"query": "",
"token": f"{Query_Token}", # 微信公众号的查询token,每天都会变化
"lang": "zh_CN",
"f": "json",
"ajax": 1
}
# 设置请求头,参数为微信公众平台-订阅号cookie
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36',
'Cookie':f'{cookie}'
}
# 向指定公众号的文章查询接口发送信息,并解析为json格式
resp = requests.get(url=base_url,headers=headers,params=params).json()
if resp['base_resp']['err_msg'] == 'freq control':
print("请求频率过高,需要等一段时间")
if resp['base_resp']['err_msg'] == 'invalid csrf token':
print("请检查请求url中的token参数,第34行~~")
# 返回结果为该公众号最近2天次已发布文章概要信息
lists = resp['app_msg_list']
# 对字典内容进行解析
for i in range(0,len(lists)):
title = lists[i]['title'] # 文章标题
digest = lists[i]['digest'] # 文章摘要
link = lists[i]['link'] # 文章链接
# 对创建时间戳解析
dateobject = datetime.datetime.fromtimestamp(lists[i]['create_time'])
day = str(dateobject.date()) # 文章发表时间--天
hour = str(dateobject.hour) # 文章发表时间--小时
minute = str(dateobject.minute) # 文章发表时间--分钟
publish_time = f"{hour}:{minute}" # 文章发表时间
articl_list = [offical_account,title,digest,link,day,publish_time]
# 利用正则筛选关键title信息,判断该文章是否需要关注
match = re.search(rule,title,flags=re.IGNORECASE)
if match:
print(title)
articl_list.append("True")
# 将文章数据汇总到总表中
aritcle_lists.append(articl_list)
def query(cookie,Query_Token):
Official_Account_list = ['Tenable安全','长亭科技','青藤云安全','亚信科技','绿盟科技','奇安信']
for Official_Account in Official_Account_list:
print(f"当前正在爬取的公众号是:{Official_Account}")
query_info(Official_Account,cookie,Query_Token)
# 等待三秒,防止频率过高,接口被封锁
time.sleep(3)
data = pd.DataFrame(aritcle_lists,columns=['安全厂商',"文章标题",'文章摘要','文章链接','发布日期','发布时间','需要关注']);
# 计算时间戳,并且作为表单名
timestamp = int(time.time())
file_path = 'excel/'+str(timestamp)+".xlsx"
#输出表格,保存到excel文件夹
data.to_excel(file_path,index=False)
return file_path
```
## 四、后续
- 当前存在的难点在于`cookie`以及请求`token`都是变量,故而难以实现持久化运行~~~
- 解决思路1,微信公众号的[api调用](https://developers.weixin.qq.com/doc/offiaccount/Getting_Started/Overview.html)
- 解决思路2,利用[playwright](https://playwright.dev/),模拟用户操作浏览器,每天在后台获取需要的`cookie`和`token`参数,存入环境变量中,覆盖上一天的数据,以此实现代码的可持续化。

记一次对微信公众号的爬虫

